In this article, we will find something out about CAP theorem. Let’s get started.
Table of contents
- Introduction to CAP theorem
- Consistency
- Availability
- Partition Tolerance
- Example with CAP theorem
- How to choose databases to satisfy CAP theorem
- When to use
- Benefits and Drawbacks
- Wrapping up
Introduction to CAP theorem
-
Distributed system
It’s a collection of interconnected nodes that all share data. A client can write data to a distributed system by talking to any one of these nodes.
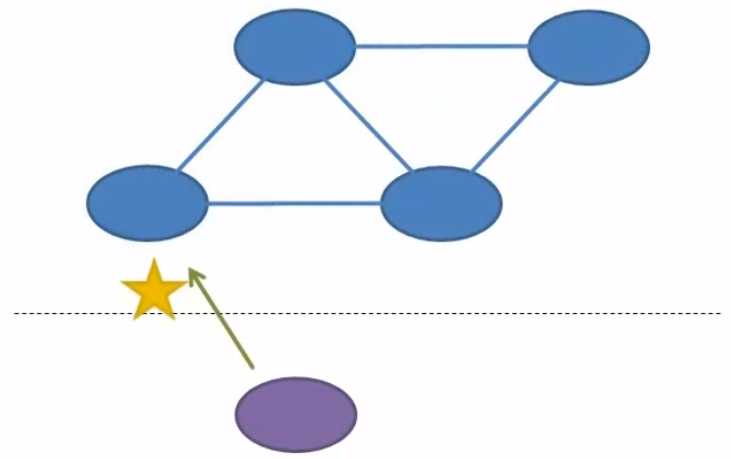
And then the client can read data from the distributed system by talking to either that same node or a different node.
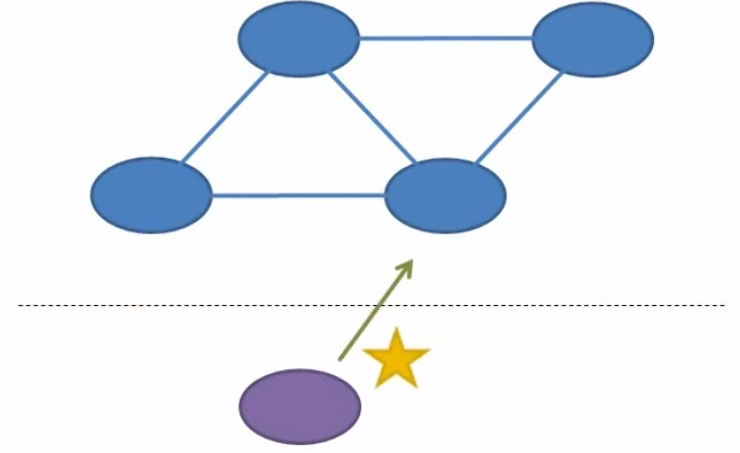
-
CAP theorem
CAP stands for Consistency, Availability, and Partition Tolerance.
CAP theorem, also named Brewer’s theorem after the computer scientist Eric Brewer postulated this theorem back in the 2000.
This theorem talks about how the system reacts when it gets a write request followed by a read request. The theorem states that for any given pair of requests, a write followed by a read, a distributed system can promise to guarantee only two out of three attributes.
These attributes contains:
- Consistency
- Availability
- Partition Tolerance
Consistency
It means that the system guarantees to read data that is at least as fresh as what we just wrote. So, whether the client reads from the same node that we just wrote to or from a different node, that node is not allowed to return stale data. So somebody else might have written something newer and the client might see their change, but consistency guarantees that the client will not see older data than what it just wrote.
All nodes see the same data at the same time. Consistency is achieved by updating several nodes.
-
Eventual Consistency
Eventual Consistencyis a consistency model which enables the data store to be highly available. It is also known as optimistic replication, and is key to the distributed system.For example:
In facebook, if we like a post of our friend that lives in Africa. Immediately, we will see the the number of list for this post was increased. But our friend in Africa still do not see the number of like increased. Because it takes so much time to move data from Asian to Africa to update all nodes. But when she refreshes her web page after a few seconds the number of like is updated.
So the data was initially inconsistent but eventually got consistent across the server nodes deployed around the world. This is called eventual consistency.
Eventual consistency is suitable for use cases where the accuracy of values doesn’t matter. But some cases we must not use eventual consistency such as in banking, stock markets.
-
Strong Consistency
Strong Consistencysimply means the data has to be strongly consistent at all times. All the server nodes across the world should contain the same value of an entity at any point in time. And the only way to implement this behaviour is by locking down the nodes when being updated.To implement Strong consistency, when we need to update all remained nodes, access to other nodes blocked until the replication completes.
-
Drawback
The performance of strongly consistency system can suck. That can make the system less useful. Because when we have some times to update something such as phone number. We have to wait for some minutes to hours to databases update completely. It is annoyed.
-
Availability
It means that a non-failing node will give the client a reasonable response (only success or failure) within a reasonable amount of time. Now all that’s relative, but what that really means is that it won’t hang definitely, and it won’t return an error. This applies to both the read and to the write request.
So, that means that the write request will acknowldge that the data was actually written, and the read request will return valid data. Neither of these requests can return error, and neither one is allowed to hang indefinitely. So, this attribute only applies to non-failing nodes. A node itself could actually be down, and the system would remain available. If the client is able to get access to any non-failing node and that node responds without an error in a reasonable amount of time, then the availability guarantee is upheld.
Partition Tolerance
Partition tolerance guarantees that a distributed system will continue to function in the face of network partitions. A network partition is a breaking connectivity. It means that nodes within the system cannot communicate with one another. A partition could be isolated to just the connection between two specific nodes or it could run through the entire network.
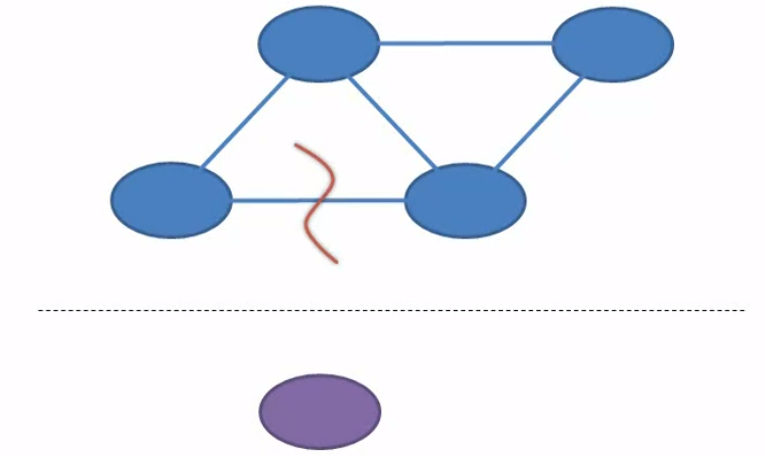
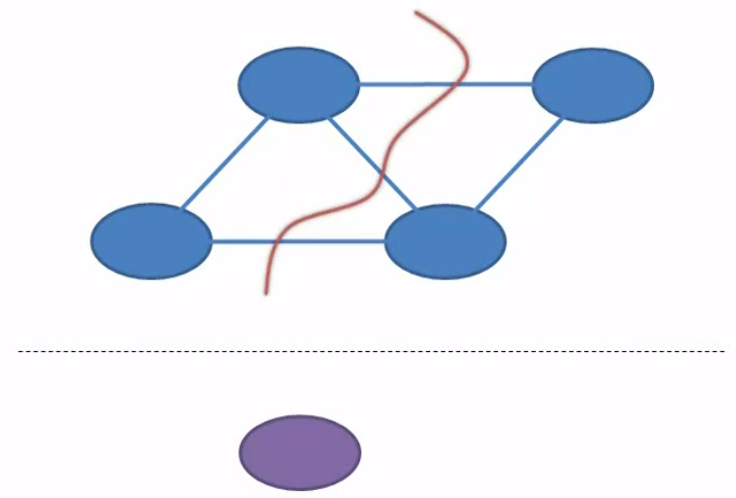
On the other hand, a partition could be just a temporary loss of connectivity like may be the loss of a single packet due to line noise or a partition could refer to something permanent like a backhoe cutting through a buried cable. But if the distributed system continues to function when the network is partitioned, then it’s said to be partition tolerant.
Example with CAP theorem
Assuming that our system is in case of a network failure, when a few of the nodes of the system are down. So, following with CAP theorem, we have to make a choice between Availability and Consistency.
If we pick Availability that means when a few nodes go down, the other nodes are available to the users for making updates. In this situation, the system is inconsistent as the nodes which are down do not get updated with the new data. At the point in time when they come back online, if a user fetches the data from them, they’ll return the old values they had when they went down.
If we pick Consistency, we have to lock down all the nodes for further writes until the nodes which have gone down come back online. This would ensure the Strong Consistency of the system as all the nodes will have the same entity values.
So, picking between Availability and Consistency largely depends on our use case and the business requirements.
How to choose databases to satisfy CAP theorem
Below is an image that describe the coordination between CAP properties.
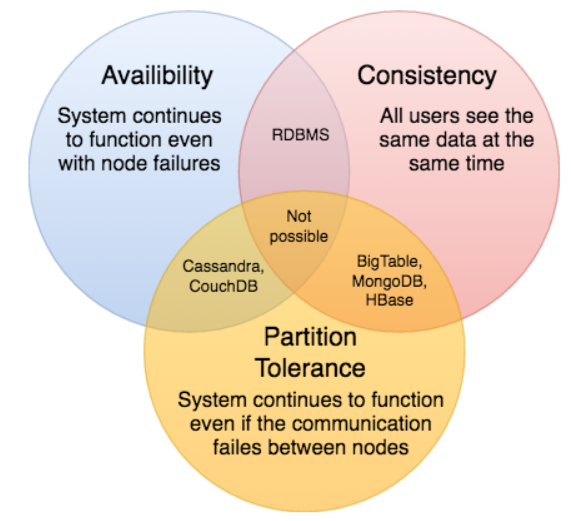
-
Consistency - Partition Tolerance Databases
Our expectation is that we need consistency property, even if the partition tolerence property happens. It means that we get the same lastest data for this case.
But if a node goes down, the system will be wait for all nodes that are available. If they’re available, the synchronization about data will happen between nodes. So when we send request to this system, we can receive timeout error because this system does not respond something.
For example, MySQL has Replication mode with one master and multiple slave. When a write request to a master, this will be pass to all slaves. If a slave does not respond, our system will wait for it in available state.
Some database types that we can use:
- Big Table
- MongoDB
- HBase
- Redis
- CockroachDB
When to use:
- When our business requirements want the atomic reads and writes.
-
Availability - Partition Tolerance Databases
In the case that our databases where a place that contains log information, or activity of users, …, we only want to capture as much information as possible about what a user or customer is doing. The information could be stale.
It means that we only need to access these databases when the connection of nodes break down. After their connection will be resolved, the synchronization about data between nodes will be applied. But it does not guarantee that the data that we capture from the partitioned node is the latest data.
Some AP databases:
- Cassandra
- DynamoDB
- Riak
- CouchDB
When to use:
- When the system needs to continue to function in spite of external errors.
- When the system only want to access data without the status of that data, it can be stale or not.
-
Consistency - Availability Databases
Some database types:
- sing-node relational databases.
When to use
-
When we think about database architecture design.
-
When we want to select database types for our system based on the busines goals, and the customer expectations.
Benefits and Drawbacks
-
Benefits
- It helps us to think about the effective way to choose, design database systems.
-
Drawbacks
- The CAP theorem only offers us to choose between Consistency and Availability. It does not provide a way that is balance between Consistency and Availability.
Wrapping up
-
Consistency means that data is the same across the cluster, so we can read/write to/from any node and get the same data.
-
Availability means the ability to access the cluster even if a node in the cluster goes down.
-
Partition Tolerance means that the cluster continues to function even if the communication between two nodes breaks down but none of them goes down.
-
Understanding about the CP/AP databases, which types that our application needs.
Refer:
Patterns for Building Distributed systems for The Enterprise - Michael Perry
https://en.wikipedia.org/wiki/CAP_theorem
https://towardsdatascience.com/cap-theorem-and-distributed-database-management-systems-5c2be977950e
Consistency
https://blog.container-solutions.com/what-is-eventual-consistency-and-why-is-it-so-cool
https://en.wikipedia.org/wiki/Eventual_consistency
https://stackoverflow.com/questions/5466012/nosql-and-eventual-consistency-real-world-examples
https://www.elastic.io/rebound-practical-application-of-eventual-consistency/
Choose database based on CAP theorem
https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html