All content of this article is refer from the website https://employment.en-japan.com/engineerhub/entry/2017/09/05/110000.
Table of contents
- Some points to compare between MySQL and PostgreSQL
- Non-blocking of DDL operation
- DML sentence performance
- Table join (JOIN) algorithm
- Separation level of transaction processing
- Stored procedures and triggers
- Logical type and physical type of replication
- Convenient function only in either DB
- Looseness of data type, type conversion, character string comparison
- Wrapping up
Some SQL commands
Before jumping into comparing between MySQL and PostgreSQL, we will read up on about some sql commands that utilizes:
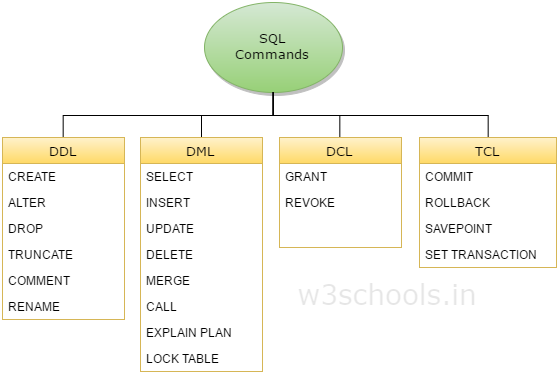
Generally speaking, SQL will contains some commands:
-
DDL - Data Definition Language
It deals with database schemas and descriptions, of how the data should reside in the database.
- CREATE – to create database and its objects like (table, index, views, store procedure, function and triggers)
- ALTER – alters the structure of the existing database
- DROP – delete objects from the database
- TRUNCATE – remove all records from a table, including all spaces allocated for the records are removed
- COMMENT – add comments to the data dictionary
- RENAME – rename an object
-
DML - Data Manipulation Language
It deals with data manipulation, and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE etc, and it is used to store, modify, retrieve, delete and update data in database.
- SELECT – retrieve data from the a database
- INSERT – insert data into a table
- UPDATE – updates existing data within a table
- DELETE – Delete all records from a database table
- MERGE – UPSERT operation (insert or update)
- CALL – call a PL/SQL or Java subprogram
- EXPLAIN PLAN – interpretation of the data access path
- LOCK TABLE – concurrency Control
-
DCL - Data Control Language
It includes commands such as GRANT, and mostly concerned with rights, permissions and other controls of the database system.
- GRANT – allow users access privileges to database
- REVOKE – withdraw users access privileges given by using the GRANT command
-
TCL - Transaction Control Language
It deals with transaction within a database.
- COMMIT – commits a Transaction
- ROLLBACK – rollback a transaction in case of any error occurs
- SAVEPOINT – to rollback the transaction making points within groups
- SET TRANSACTION – specify characteristics for the transaction
Some points to compare between MySQL and PostgreSQL
Below is some particular features that we want to compare between MySQL and PostgreSQL.
- Non-blocking of DDL operation
- DML sentence performance
- Table join (JOIN) algorithm
- Separation level of transaction processing
- Stored procedures and triggers
- Logical type and physical type of replication
- Convenient function only in either DB
- Looseness of data type, type conversion, character string comparison
Non-blocking of DDL operation
-
MySQL
Many DDL operations will not be blocked in MySQL from version 5.6.
-
PostgreSQL
But with DDL operations such as adding columns, PostgreSQL will rewrite the table. It means that table will be locked, other transactions will not be accessible to it.
But in PostgreSQL, to apply ALTER TABLE to the production database efficiently, we can use an external tool pg_repack. It allows you to perform REINDEX and some ALTER TABLE operations with minimal locking.
DML sentence performance
-
SELECT command
Both MySQL and PostgreSQL use SELECT command in a similar way. But normally, when working with large records, SELECT command goes with ORDER BY command by default, so our records need to sort in some orders. MySQL have the poor sorting algorithm when compared to PostgreSQL in large data.
To dig deeper into the sorting algorithm in MySQL, we can refer sorting MySQL
But MySQL is faster than PostgreSQL when we want to get the smaller number of records such as get 10, 100 new data.
-
UPDATE command
MySQL has the better performance than PostgreSQL because PostgreSQL will do the following steps:
- In a specific record, it will set a deleted flag.
- Then, it inserts a new record with the changed data.
- Finally, once data has been inserted into rows within the database, those rows can have one or more of their columns values modified through use of the SQL UPDATE command. To understand some cases of updating data, we can read about the article Modifying Rows with UPDATE, Oreilly.
But MySQL will directly overwrite the value of that record with UPDATE command.
-
DELETE command
MySQL has the slower DELETE query than PostgreSQL.
We know that MySQL will create the clustered index based on some conditions:
- When we define a primary key on our table, InnoDB storage engine will use it as the clustered index.
- If a table do not have primary key, MySQL will choose the first unique index of a table as a clustered index.
- It a table has no primary key or the unique index, MySQL will generate a hidden clustered index named GEN_CLUST_INDEX.
Then if we want to index other fields that will be accessed frequently, they are called as the secondary indexes, it will contain the primary key as the value of node in that second index.
Finally, when MySQL delete a record, firstly, it need to delete its record’s primary key in the secondary indexes, then, in the clusted index. Continuously, MySQL will synchronize these data into disk. It takes so much time to do this action. However, MySQL fixed it in version 5.5. The asynchronous change in the secondary indexes and clustered index, and merge changes to disk, is working when MySQL server is idle.
Table join (JOIN) algorithm
There are three types of commonly used table join algorithms:
- Nested Loop Join
- Hash Join
- Sort Merge Join
MySQL basically supports only nested loop joins. This is because MySQL is based on the design philosophy of “I do not support complex algorithms as much as possible”. MySQL was originally used in embedded systems before it was used in web applications. It’s necessary to run the database in a disk or memory with a very small capacity of the embedded device, and it has been designed with the policy of the dropping complicated algorithms as much as possible.
But PostgreSQL will support three join types.
When there is a large amount of data to be joined, it’s better to use Hash Join or Sort merge join. A Sort merge join is better if the data is already sorted, otherwise a Hash Join is recommeded.
Nested Loop Join are the best choice when the tables being joined have a small amount of data and the other has a large amount of data. Or when the inner table side can use index scan.
Separation level of transaction processing
There are four transaction isolation level:
-
REPEATABLE READ
It’s the most restrictive isolation level.
Read locks and write locks are acquired. It means that reading transactions block writing transactions (but not other reading transactions), and writing transactions block all other transactions.
This isolation level does not permit dirty reads or non-repeatable reads. It also does not acquire a range lock, which means it permits phantom reads. A read lock prevents any write locks from being acquired by other concurrent transaction. This level can still have some scalability issues.
-
READ COMMITTED
Read locks are acquired and released immediately, and write locks are acquired and released at the end of the transaction. It means that reading transactions do not block other transactions from accessing a row. However, an uncommitted writting transaction blocks all other transactions from accessing the row.
Dirty read are not allowed in this isolation level, but non-repeatable reads and phantom reads are permitted. By using the combination of persistent context and versioning, we can achieve the REPEATABLE READ isolation level.
-
READ UNCOMMITTED
It’s the lowest isolation level.
Changes made by one transaction are made visible to other transactions before they’re committed. All types of reads, including dirty reads, are permitted, but do not permit lost updates. This isolation level is not recommended for use. If a transaction’s uncommitted changes are rolled back, other concurrent transaction may be seriously affected.
One transaction may not write to a row if another uncommitted transaction has already written to it. Any transaction may read any row, however. This isolation level may be implemented using exclusive write locks.
-
SERIALIZABLE
It’s the highest isolation level.
Transactions are executed serially, one after the other. This isolation level allows a transaction to acquire read locks or write locks for the entire range of data that it affects. The SERIALIZABLE isolation level prevents dirty reads, non-repeatable reads, and phantom reads, but it can cause scalability issues for an application.
Belows are some concepts about several phenomena with an example is that we have two transactions work on the users table that has some fields - id, name, and age.
| id | name | age |
|---|---|---|
| 1 | Joe | 20 |
| 2 | Jill | 21 |
-
Dirty read
A dirty read occurs when a transaction is allowed to read data from a row that has been modified by another running transaction and not yet committed.
For example:
Transaction 1 Transaction 2 SELECT age FROM users WHERE id = 1; // read 20 UPDATE users SET age = 21 WHERE id = 1; // do not commit SELECT age FROM users WHERE id = 1; // read 21 ROLLBACK; // it can happen exceptions so that this transaction 2 will rollback We can find that the two times transaction 1 read, each time the data is different. And finally, transaction 2 will rollback, then our latest read data will be wrong.
-
Non-repeatable read
A non-repeatable read occurs when a transactions reads a record twice, and the record state is different between the first and the second read. This happens when another transaction updates the state of the record between the two reads.
For example:
Transaction 1 Transaction 2 SELECT * FROM users WHERE id = 1; UPDATE users SET age = 21 WHERE id = 1; COMMIT; SELECT * FROM users WHERE id = 1; COMMIT; Transactions 2 commit successfully, so transaction 1 will see that change, but transaction 1 will see different values after query.
At the SERIALIZABLE and REPEATABLE READ isolation level, RDBMS will return the old value for the second SELECT. At READ COMMITTED and READ UNCOMMITTED, RDBMS will return the updated value.
There are two strategies to prevent non-repeatable read:
-
Using lock-based concurrency control
At the REPEATABLE READ isolation mode, the row with id = 1 would be locked, thus blocking Transaction 2 until Transaction 1 was committed or rolled back.
At the READ COMMITTED mode, the second time of query in Transaction 1 is happened, the age would have changed.
-
Using MVCC - multiversion concurrency control
When a transaction does a read on a database, a snapshot is created, and the data is read from the snapshot. This process isolates the data from other concurrent transactions. When the transaction modifies a record, the database creates a new record version instead of overwriting the old records. This mechanism gives good performance because lock contention between concurrent transaction is minimized. In fact, lock contention is eliminated between read locks and write locks, which means that read locks never block a write lock. Most concurrent databases such as Oracle, MySQL, SQL Server, and PostgreSQL implement MVCC for concurrency.
Comes back to our example, Transaction 2 is permitted to commit first, which provides for better concurrency. However, Transaction 1, which commenced prior to Transaction 2, must continue to operate on a past version of the database - a napshot of the moment it was started. When Transaction 1 eventually tries to commit, RDBMS check if the result of committing Transaction 1 would be equivalent to the schedule of
Transaction 1 --> Transaction 2. If it is, then Transaction 1 can proceed, If it can not be seen to be equivalent, however, Transaction 1 must roll back with a serialization failure.At the SERIALIZABLE isolation level, both SELECT queries see a snapshot of the database taken at the start of Transaction 1. Therefore, they return the same data. However, if Transaction 2 then attempted to UPDATE that row as well, a serialization failure would occur and Transaction 1 would be forced to roll back.
At the READ COMMITTED isolation level, each query sees a snapshot of the database taken at the start of each query. Therefore, they each see different data for the updated row. No serialization failure is possible in this mode (because no promise of serializability is made), and Transaction 1 will not have to be retried.
-
-
Phantom read
A phantom read occurs when new rows are added or removed by another transaction to the records being read.
This can occur when range locks are not acquired on performing a SELECT … WHERE operation.
For example:
Transaction 1 Transaction 2 SELECT * FROM users WHERE age BETWEEN 10 AND 30; INSERT INTO users(id, name, age) VALUES (3, ‘Bob’, 27); COMMIT; SELECT * FROM users WHERE age BETWEEN 10 AND 30; COMMIT; Transaction 1 executed the same query twice. If the highest level of isolation were maintained, the same set of rows should be returned both times, and indeed that is what is mandated to occur in a database operating at the SQL SERIALIZABLE isolation level. However, at the lesser isolation levels, a different set of rows may be returned the second time.
In the SERIALIZABLE isolation mode, Query 1 would result in all records with age in the range 10 to 30 being locked, thus Query 2 would block until the first transaction was committed. In REPEATABLE READ mode, the range would not be locked, allowing the record to be inserted and the second execution of Query 1 to include the new row in its results.
-
Lost update
Two transactions both update a row and then the second transactions aborts, causing both changes to be lost. This occurs in systems that don’t implement any locking. This concurrent transaction aren’t isolated.
-
Second lost updates problem
A special case of an non-repeatable read. Imagine that two concurrent transactions both read a row, one writes to it and commits, and then the second writes to it and commits. The changes made by the first writer are lost.
So, summarize the reads that are permitted for various isolation reads.
| Isolation Level | Lost update | Second lost update | Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|---|---|
| Serializable | _ | _ | _ | _ | _ |
| Repeatable Read | _ | _ | _ | _ | May occur |
| Read Committed | _ | _ | _ | May occur | May occur |
| Read Uncommitted | _ | _ | May occur | May occur | May occur |
By default, MySQL use REPEATABLE READ isolation level. With this transaction isolation level, there is no concern that the data to be read will be changed by another transaction. However, phantom read may occur. MySQL uses mechanism called Next Key Locking to avoid this problem.
By default, PostgreSQL use READ COMMITTED isolation level. With this way, phantom read and non-repeatable read may occur, so it is necessary to be careful. In PostgreSQL, even if the transaction isolation level is changed to REPEATABLE READ, the Next Key Locking is not taken and phantom read is prevented by a different method. Therefore, it may be better than MySQL in that it is easier to prevent lock contention.
Stored procedures and triggers
PostgreSQL has the advantage that external procedures using Python etc. can be used in addition to SQL.
But MySQL only supports store procedure in SQL. In MySQL version 5.6 and earlier, it can only set up to 6 multi-triggers per table. Also, since only one BEFORE INSERT TRIGGER could be set per table, there were quite some restrictions. Currently, the number of triggers is no longer limited. However, MySQL only supports the trigger FOR EACH ROW without FOR EACH STATEMENT.
Logical type and physical type of replication
Logical replication means that each slave will copy query and implement it by itself. Physical replication means that each slave will copy the changed records from master, then update corresponding records.
Before MySQL version 5.6, logical replication will be set by default but since version 5.7, physical replication will be apply be default.
PostgreSQL will only support physical replication.
Convenient function only in either DB
-
PostgreSQL
PostgreSQL has only features that are suitable for aggregation, such as window functions that can apply aggregate functions to partially cut out result sets and WITH clauses that can create subqueries before executing a SELECT statement. For this reason, PostgreSQL was stronger in the processing of the analysis system.
PostgreSQL supports to handle information of maps and geometric data by using PostGIS tool.
-
MySQL
With window functions, WITH clauses, MySQL will be introduced from version 8.0.
MySQL supports parallel query to take advantage of multiple CPUs to execute queries for faster processing.
Looseness of data type, type conversion, character string comparison
-
MySQL
In MySQL before version 5.6, Looseness of data type was often a problem. However, since 5.7, it was fixed, but there are still fewer cases where bugs are caused by data types.
For example,
(int) 1 = (string) '1' = (string) '1Q84'And there are some cases where the type is implicitly converted. For example, if we subtract the number “1” from the date type “2017-07-01”, the integer “20170700” will be returned.
MySQL is case insensitive in string comparison by default.
-
PostgreSQL
In PostgreSQL, users need to handle the conversion by themself.
Wrapping up
-
MySQL is suitable for simple web services. It’s like getting a set of data and display that data. For example, a service that display the beginning of the timeline and scrolls down to read the next data, such as Twitter, is particularly suitable for MySQL.
-
PostgreSQL has the greatest advantage of being multi-functional. So it is suitable for systems where its feature can be used. It’s often used in analytical systems.
-
In the latest version of MySQL, it’s improved about performance and some functionalities. So the differences between MySQL and PostgreSQL will be reduced.
Refer:
https://employment.en-japan.com/engineerhub/entry/2017/09/05/110000
https://stackoverflow.com/questions/2578194/what-are-ddl-and-dml