Table of contents
- Given problem
- Solution with Rete algorithm
- The differences between Rete algorithm and Brute force approach
- When to use
- Benefits and Drawbacks
- Some questions about Rete algorithm
- Source code
- Wrapping up
Given problem
This article will be used to note everything about the simple version of Rete algorithm that I studied.
Solution with Rete algorithm
-
Some concepts that use in Rete algorithm
- Facts
- Rules
-
Production Memory
The Production Memory is a set of productions or rules. A production is specified as a set of conditions, collectively called the left-hand side - LHS, and a set of actions, collectively called the right-hand side - RHS.
Conditions may contain variables.
-
Working Memory
The Working Memory - WM is a set of items which represent Facts about the system’s current situation. Each item in WM is called a Working Memory Element - WME.
In Rete algorithm, WME has the form of triples that look like:
identifier ^attribute value.No variables are allowed in WMEs.
-
Token
The descriptions of WM changes that are passed into the black box are called tokens.
A token is an ordered pair of a tag and a list of data elements.
In the simplest implementations of the Rete algorithm, there are only two tags.
- The tag + indicates that something has been added to the WM.
- The tag - indicates that something has been deleted from the WM.
When an element is modified, two tokens are sent to the black box. One token indicates that the old form of the elements has been deleted from WM, and the other the new form of the element has been added.
-
How production matches working memory
A production is said to match the current WM if all its conditions match items in the current working memory, with any variables in the conditions bound consistently.
The match algorithm’s job is to determine which productions in the system match the current WM, and for each one, to determine which WMEs match which conditions.
-
The structure of Rete algorithm
There are two parts in this algorithm.
-
Alpha part
The alpha part performs the constant tests on the WMEs. Its output is stored in the Alpha Memories - AM, each of which holds the current set of WMEs passing all the constant tests of an individual condition.
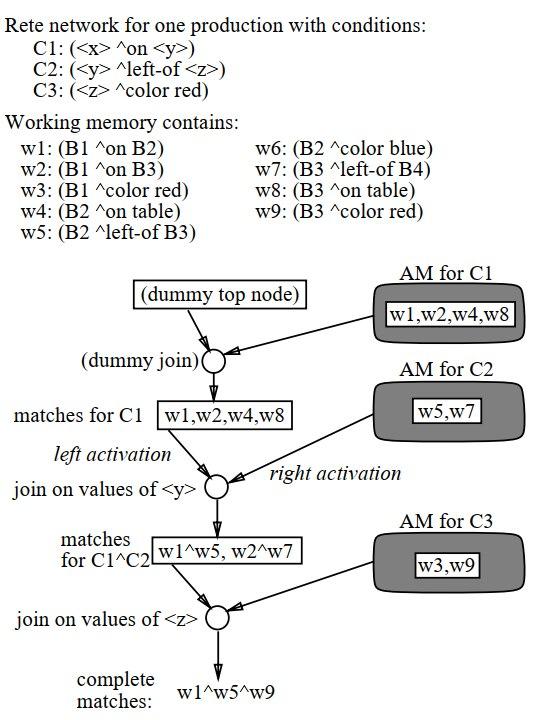
In most versions of Rete, the alpha network performs not only constant tests but also intra-condition variable binding consistency tests, where one variable occurs more than once in a single condition.
So, in the Alpha part, we will have some classes:
-
AlphaMemory
It contains a list of WMEs that match each condition in each node in a given node branch and a list of its successors (join nodes attached to it).
-
ConstantTestNode
It contains a pattern, Alpha Memory, and the children of ConstantTestNode.
This is a node that contains a specific pattern from a condition. This node’s functionality is to minimise condition redundancy.
-
AlphaTopNode
It saves the root node of the Alpha Network.
-
WME - A Working Memory Element
It contains three fields that satisfy: id ^attribute value.
Whenever a new WME is filtered through the alpha network and reaches an alpha memory, we simply add it to the list of other WMEs in that memory, and inform each of the attached join nodes.
-
-
Beta part
The beta part of the network contains join nodes and beta memories.
Join nodes perform the tests for consistency of variable bindings between conditions.
Beta memories store partial instantiations of productions, for example, combinations of WMEs which match some but not all of the conditions of a production. These partial instantiations are called tokens. So, each token represents a sequence of WMEs - specially, a sequence of k WMEs (for some k) satisfying the first k conditions (with consistent variable bindings) of some productions.
In the Beta part, we have:
-
Token
public class Token { private Token parent; // points to the higher token 1, ..., i - 1 private WME wme; // contents of token i } -
BetaMemory
A beta memory node stores a list of the tokens it contains, plus a list of its children (other nodes in the beta part of the network).
Whenever a beta memory is informed of a new match (consisting of an existing token and some WMEs), we build a token, add it to the list of the beta memory, and inform each of the beta memory’s children.
Every time a beta memory node is activated, it creates and stores a new token.
public class BetaMemory extends ReteNode { private List<Token> tokens; } -
JoinNode
A join node can incur in a right activation when a WME is added to its alpha memory, or a left activation when a token is added to its beta memory. In either case, the node’s other memory is searched for items having variable bindings consistent with the new item; if any are found, they are passed on to the join node’s children.
From the data common to all nodes (the Rete node structure), we already have the children, the parent field automatically gives us a pointer to the join node’s beta memory (the beta memory is always its parent).
Then, we need two extra fields for a join node such as the alpha memory, and a list of TestAtJoinNodes.
-
TestAtJoinNode
The TestAtJoinNode structure specifies the locations of the two fields whose values must be equal in order for some varibles to be bound consistently.
public class TestAtJoinNode { private WMEFieldType fieldArg1; private WMEFieldType fieldArg2; private int condNumberOfArg2; }fieldArg1 is one of the three fields in the WME (in the alpha memory), while fieldArg2 is a field from a WME that matched some earlier conditions in the production (i.e, part of the token in the beta memory).
-
ProductionNode
A production node may store tokens, just as beta memories do; these tokens represent complete matches for the production’s conditions. In traditional production system, the set of all tokens at all production nodes represents the conflict set.
On a left activation, a production node will build a new token, or some similar representation of the newly found complete match. It then signals the new match in some appropriate way.
In general, a production node also contains a specification of what production it corresponds to - the name of the production, its right-hand-side actions, … A production node also contains information about the names of the variables that occur in the production.
-
Working memory changes are sent through the alpha network and the appropriate alpha memories are updated. These updates are then propagated over to the attached join nodes, activating those nodes. If any new partial instantiations are created, they are added to the appropriate beta memories and then propagated down the beta part of the network, activating other nodes. Whenever the propagation reaches the bottom of the network, it indicates that a production’s conditions are completely matched. This is commonly implemented by having a specical node for each production (called its production node) at the bottom of the network.
The bulk of the code for the Rete algorithm consists of procedures for handling the various node activations.
- The activation of an alpha memory node is handled by adding a given WME to the memory, then passing the WME on to the memory’s successors (the join nodes attached to it).
- The activation of a beta memory node is handled by adding a given token to the memory and passing it on to the node’s children (join nodes).
In general, an activation of some nodes from another node in the beta network is called a left activation. An activation of some nodes from an alpha memory is called a right activation.
A join node can incur two types of activations:
- a right activation when a WME is added to its alpha memory(i.e, the alpha memory that feeds into it)
- a left activation when a token is added to its beta memory (the beta memory that feeds into it).
After using Rete algorithm, its output is a conflict set. Conflict set mans, for the same fact or condition, it might be possible that more than one rule is satisfied. So it returns the set of conflict rules.
-
The differences between Rete algorithm and Brute force approach
Belows are the two reasons that Rete algorithm runs faster than naive approach.
-
State-saving
After each change to WM, the state (results) of the matching process is saved in the alpha and beta memories. After the next change to WM, many or most of these results are usually unchanged, so Rete avoids a lot of recomputation by keeping these results around in between successive WM changes.
Rete is designed for systems where only a small fraction of WMEs change in between successive times rules need to be matched. Rete’s state-saving would not be very beneficial in systems where most WMEs change each time.
-
Sharing of nodes between productions with similar conditions
Different kinds of sharing occur in different parts of the network. There can be sharing within the alpha network, when two or more productions have a common condition, Rete uses a single alpha memory for the condition, rather than creating a duplicate memory for each production.
When to use
-
The Rete algorithm is suited to scenarios where forward chaining and inferencing is used to calculate new facts from existing facts, or to filter and discard facts in order to arrive at some conclusions.
-
It is also exploited as a reasonably efficient mechanism for performing highly combinatorial evaluations of facts where large numbers of joins must be performed between fact tuples.
Benefits and Drawbacks
-
Benefits
-
high performance
Many rules often contain similar patterns or group of patterns. Rete algorithm pools the common components so that they need not be computed again.
-
-
Drawbacks
-
memory intensive
Saving the state of the system using pattern matches and partial matches considerable amount of memory.
The space complexity of Rete is of the order of O(RFP), where R is the number of rules, F is the number of asserted facts, and P is the average number of patterns per rule.
-
Some questions about Rete algorithm
- Why do AlphaMemory, BetaMemory needs to contains WMEs?
Source code
Below is the source code of the sample of this Rete algorithm that using Java language:
Wrapping up
- Other approaches to perform rule evaluation, such as the rule of decision trees, or the implementation of sequential engines, may be more appropriate for simple scenarios, and should be considered as possible alternatives.
Refer:
https://en.wikipedia.org/wiki/Rete_algorithm
https://techondec.wordpress.com/2013/11/05/writing-simpler-rules/
https://techondec.wordpress.com/2011/03/14/rete-algorithm-demystified-part-2/
https://www.sparklinglogic.com/rete-algorithm-demystified-part-2/
https://medium.com/@tekaround/rete-algorithm-and-drools-fd57b3290f1d
https://www.sap.com/documents/2015/09/703d5a24-577c-0010-82c7-eda71af511fa.html
https://www.drdobbs.com/architecture-and-design/the-rete-matching-algorithm/184405218
https://jess.sandia.gov/docs/71/rete.html
https://www.flexrule.com/archives/forward-chain-inference-engine-with-rete
https://docs.jboss.org/drools/release/5.3.0.Final/drools-expert-docs/html/ch01.html
https://salaboy.com/2011/06/06/drools-reteoo-for-dummies-1-intro/
EBook
Production Matching for Large Learning Systems by Robert B. Doorenbos - January 31, 1995
A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem* by Charles L. Forgy - 1982