This article is from herbertograca.com.
This post is part of The Software Architecture Chronicles, a series of posts about Software Architecture. In them, I write about what I’ve learned on Software Architecture, how I think of it, and how I use that knowledge. The contents of this post might make more sense if you read the previous posts in this series.
Domain-Driven Design was coined by Eric Evans in his fantastic book Domain-Driven Design: Tackling Complexity in the Heart of Software, published in 2003. Eric Evans book was key in formalising many of the software development concepts that today we take for granted.
I can’t make an exhaustive review of DDD in a blog post. There are just too many important concepts associated with DDD. Fortunately, that’s also not the goal here. What I will do, however, is to list the DDD concepts that I find more relevant for the way I like to organise code and how I think of Architecture: the system-wide concepts that constitute the foundations for feature development.
In this post, I’m going to write about:
- Ubiquitous language
- Layers
- Bounded contexts
- Anti-Corruption Layer
- Shared Kernel
- Generic Subdomain
Ubiquitous language
A recurrent problem in software development, revolves around understanding the code, what it is, what it does, how it does it, why it does it… it is even more complicated to understand the code if it uses a terminology different than the terminology the Domain experts use, for example, if the domain experts talk about elder users while the code talks about supervisors, this might bring a lot of confusion when discussing the application. Most of this ambiguity, however, can be solved with proper naming of classes and methods, making them express what an object is and what a method does in the context of the domain.
The main idea of using a Ubiquitous Language is to align the application with the business. This is accomplished by adopting a common language, between the business and technology, in the code. The source for the language is the business side of the company, they have the concepts that need to be implemented, but the terminology is then negotiated with the technology side of the company (meaning that the business side doesn’t always choose the best naming either) with the objective of creating a common terminology that can be used by business, technology and in the code itself without any ambiguity, a ubiquitous language. The code, classes, methods, properties and modules naming must align with the ubiquitous language. It is worth refactoring the code if needed!
Layers
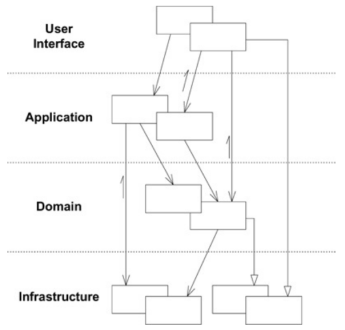
I have already talked about layering in a previous post, but I find it import at this point to remember the layers identified by DDD:
-
User Interface
Responsible for drawing the screens the users use to interact with the application and translating the user’s inputs into application commands. It is important to note that the “users” can be human but can also be other applications connecting to our API, which corresponds entirely to the Boundary objects in the EBI architecture;
-
Application layer
Orchestrates Domain objects to perform tasks required by the users: the Use Cases. It does not contain business logic. This relates to the Interactors in the EBI architecture, except that the Interactors were any object that was not related to the UI or an Entity and, in this case, the Application Layer only contains the objects relevant to a Use Case. This layer is where the Application Services belong, as they are the containers where the use case orchestration happens, using repositories, Domain Services, Entities, Value Objects or any other Domain object;
-
Domain layer
This is the layer that contains all the business logic, the Domain Services, Entities, Events and any other object type that contains Business Logic. It obviously relates to the Entity object type of EBI. This is the heart of the system. The Domain Services will contain the Domain logic that does not quite fit in an Entity, usually orchestrating several entities in accomplishing some domain action;
-
Infrastructure
The technical capabilities that support the layers above, ie. persistence or messaging.
Bounded contexts
In an enterprise application, the model can grow quite a lot and the size of the team working on the code base as well. This brings us to two problems:
-
The bigger the code base a developer has to work with, the bigger the cognitive load, the more difficult it is to understand the code, and therefore the possibility of introducing bugs and errors in judgement;
-
The more developers work on the same codebase, the more difficult it is to coordinate efforts and have a common technical and domain vision of the application.
In other words, the problem at hand becomes too big.
The usual solution to a big problem is to break it up into smaller pieces, and this is exactly where the “bounded contexts” come into play.
Two subsystems commonly serve very different user communities
Eric Evans 2014, Domain-Driven Design Reference
Bounded contexts define a context where an isolated part of the model applies. The isolation can be achieved by decoupling technical logic, by code base segregation, by database schema segregation and also in terms of team organisation. The degree to which we isolate the bounded context is, as usual, dependent on the actual situation: the needs and possibilities we have.
Interesting enough, this was not a completely new concept. Ivar Jacobson wrote about subsystems in his book, back in 1992, eleven years before Eric Evans!
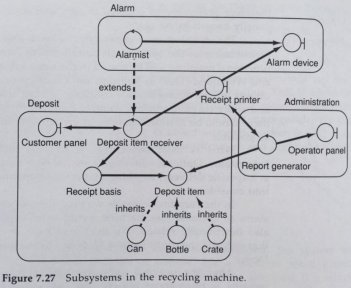
Already back then he had quite a few very concrete ideas about this subject:
-
The system thus consists of a number of subsystems which can contain subsystems of themselves. At the bottom of such a hierarchy are the analysis objects. Subsystems are thus a way of structuring the system for further development and maintenance.
-
The task of the subsystems is to package the objects so that the complexity is reduced.
-
All the objects having to do with a particular part of the functionality will be placed in the same subsystem.
-
The aim is to have a strong functional coupling within a subsystem and a weak coupling between subsystems (nowadays known as low coupling and high cohesion)
-
[One subsystem] should therefore preferably be coupled to only one actor, since changes are usually caused by an actor
-
[…] begin by placing the control object in a subsystem, and then place strongly coupled entity objects and interface objects in the same subsystem
- All objects which have a strong mutual functional coupling will be placed in the same subsystem […]
-
Will changes in one object lead to changes in the other object? (This is now known as The Common Closure Principle – Classes that change together are packaged together – published by Robert C. Martin in his paper “Granularity” in 1996, 4 years after Ivar Jacobson book)
-
Do they communicate with the same actor?
-
Are both of them dependent on a third object, such as an interface object or an entity object?
-
Does one object perform several operations on the other? (This is now known as The Common Reuse Principle – Classes that are used together are packaged together – by Robert C. Martin in his paper Granularity in 1996, 4 years after Ivar Jacobson book)
-
-
Another criterion for the division is that there should be as little communication between different subsystems as possible (low coupling)
-
For large projects, there may thus be other criteria for subsystem division, for example:
-
Different development groups have different competence or resources, and it may be desirable to distribute the development work accordingly (the groups may also be geographically separated)
-
In a distributed environment, a subsystem may be wanted at each logical node (SOA, web services and micro services)
-
If an existing product can be used in this system, this may be regarded as a subsystem (libraries our system depends on, i.e. an ORM)
-
Anti-Corruption Layer
An anti-corruption layer is basically a middleware between two subsystems. It is used to isolate the two subsystems, making them depend on the anti-corruption layer instead of depending directly on each other. This way, if we refactor or completely replace one of the subsystems, we will only have to update the anti-corruption layer leaving the other subsystem untouched.
This is especially useful when we have a new system that we need to integrate with a legacy system. In order to not let the legacy structure dictate how we design the new system, we create an anti-corruption layer that will adapt the API of the legacy subsystem to the needs of the new subsystem.
It has 3 main concerns:
- Adapting subsystems APIs to what the client subsystems need;
- Translating data and commands between subsystems;
- Establish communication in one or several directions, as needed
This is a technique that is more logical to be used when we don’t control one or all of the subsystems, but it might also make sense to use it when we control all of the subsystems involved, even if they are well designed but simply have very different models and we want to prevent leakage from one model to another (change one subsystem to match the needs of another subsystem).
Shared Kernel
In some situations, despite our desire to have completely isolated and decoupled components, it makes sense for some domain code to be shared by multiple components.
This will allow components to stay decoupled from each other, although coupled to that same shared code, the shared kernel.
That is the case, for example, with events that are triggered by one component and listened to by another one or several components. But it can also be the case with service interfaces and even entities.
Nevertheless, we should keep the shared kernel small, and be very careful when changing it so we don’t inadvertedly break other code using it. It is important that the code in the shared kernel is not changed without consultation with the other development teams using it.
Generic Subdomain
A subdomain is a very well isolated part of the domain. A generic subdomain is a subdomain that is not specific to our application, it could be used in any similar application.
So, if we have an application which has part of it that is about finance, maybe we can use an existing finance library in our application. But either way, even if we can’t use an existing library and need to build our own, if it is a generic subdomain it is not our core business and it should be thought of as essential but not crucial. It is not the most important part of our application, so it is not where our best experts should be focused and it should even be clearly outside of the main source code, possibly installed with a dependency management tool.
Conclusion
The DDD concepts I chose to approach here are, again, mostly about single responsibility, low coupling, high cohesion, isolating logic so that our applications become more consistent, easier and faster to change and adapt to the needs of the business.
Sources
1992 – Ivar Jacobson – Object-Oriented Software Engineering: A use case driven approach
1996 – Robert C. Martin – Granularity
2003 – Eric Evans – Domain-Driven Design: Tackling Complexity in the Heart of Software
2014 – Eric Evans – Domain-Driven Design Reference